Elastic 推出全新语义重排序模型 Elastic Rerank
了解 Elastic 新的重排序模型是如何训练的以及它的性能表现。
机器学习研究
Thomas Veasey、Quentin Herreros 和 Thanos Papaoikonomou
2024 年 11 月 25 日
在本系列的前一篇博客中,我们介绍了语义重排序的概念。在本篇博客中,我们将讨论我们已经训练并在技术预览版中发布的重排序模型。
简介
Elastic 的目标之一是降低实现高质量文本搜索的门槛。基于 Lucene 构建,Elasticsearch 提供了一套丰富的、可扩展的、高度优化的全文检索原语,包括使用 BM25 评分的词汇检索、学习型稀疏检索和向量数据库。最近,我们在搜索 API 中引入了检索器的概念,它允许可组合操作,包括语义重排序。我们也在努力将高级搜索管道引入 ES|QL。
从我们的无服务器产品开始,我们将在技术预览版中发布 Elastic Rerank 模型。这是一个交叉编码器重排序模型。随着时间的推移,我们计划将其与我们的完整产品套件集成,并提供优化版本以在任何集群的 ML 节点上运行,就像我们对检索模型所做的那样。我们也一直在研究一些令人兴奋的新推理功能,这些功能将非常适合重排序工作负载,敬请期待进一步的公告。
第一个版本的目标是英文文本重排序,与我们评估的其他模型相比,它在推理成本的质量方面提供了一些显著优势。在这篇博文中,我们将讨论其架构和训练的一些方面。但首先……
性能对比
在上一篇博客中,我们讨论了在使用稀疏或稠密模型的索引成本非常高的情况下,使用 BM25 评分的词汇检索(简称 BM25)如何成为一个有吸引力的选择。然而,与 BM25 相比,较新的方法往往会显著提高相关性,特别是对于更复杂的自然语言查询。
正如我们之前讨论过的,BEIR 套件是一个高质量且广泛使用的英文检索基准测试集。MTEB 基准测试也使用它来评估文本嵌入的检索质量。它包括各种任务,包括开放域问答 (QA),而 BM25 通常难以应对。由于 BM25 代表了一种经济高效的第一阶段检索器,因此了解我们可以在多大程度上使用重排序来“修正”其相关性(以 BEIR 衡量)是很有意义的。
在下一篇博客中,我们将详细分析下表中包含的不同高质量重排序模型。这包括对其行为的更定性分析,以及对其成本相关性权衡的一些额外见解。在这里,我们遵循现有技术,并描述它们对 BM25 检索的前 100 个结果进行重排序的有效性。这是相当深度的重排序,我们不一定会推荐在 CPU 上进行推理。然而,正如我们将在下一篇博客中展示的那样,它提供了一个合理的近似值,可以了解您通过重排序可以实现的相关性提升。
| 模型 | 参数数量 | 平均 nDCG@10 |
|---|
| BM25 | - | 0.426 |
| MiniLM-L-12-v2 | 33M | 0.487 |
| mxbai-rerank-base-v1 | 184M | 0.48 |
| monoT5-large | 770M | 0.514 |
| Cohere v3 | n/a | 0.529 |
| bge-re-ranker-v2-gemma | 2B | 0.568 |
| Elastic | 184M | 0.565 |
对 BM25 检索的前 100 个文档进行 BEIR 重排序的平均 nDCG@10
为了了解不同模型的相对成本相关性权衡,我们在下图中绘制了此表。
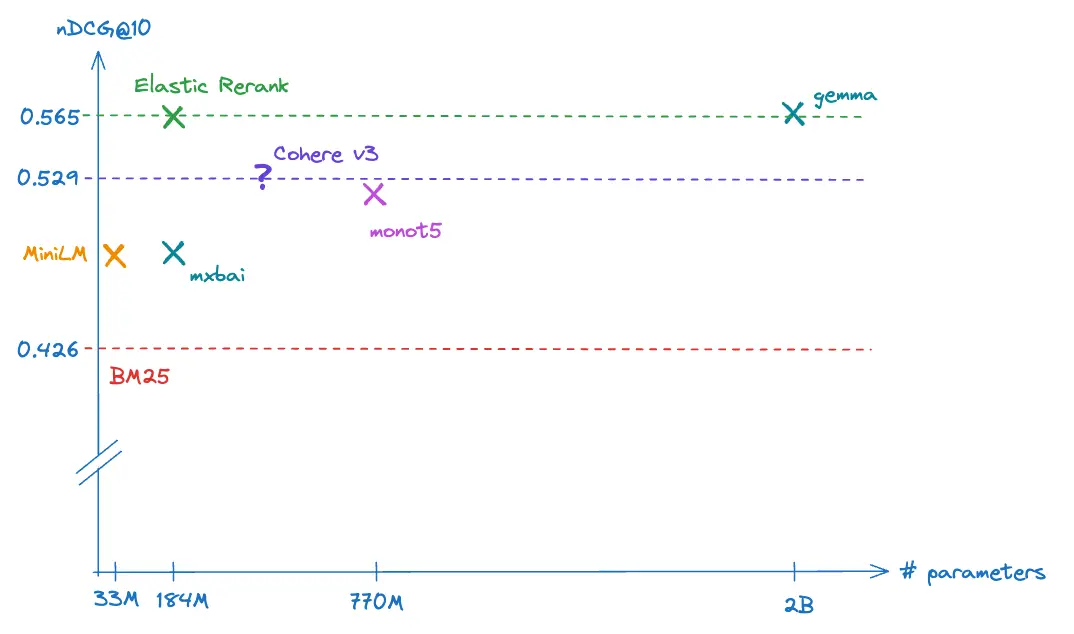
图表显示了不同模型的平均 nDCG@10 与其参数数量的对比。
图片描述:一张图表,横轴是模型的参数量,纵轴是nDCG@10的值。各个模型以点的形式展现,越靠近左上角表示模型越好(参数少,nDCG@10高)。
为了完整起见,我们还在下面展示了 Elastic Rerank 的各个数据集结果。这表示整个套件的平均改进率为 39%。在撰写本文时,这使得重排序的 BM25 在 MTEB 排行榜上排名第 20 位左右。所有更有效的模型都使用大型嵌入,至少有 1024 维,并且模型明显更大(平均比 Elastic Rerank 大 30 倍)。
| 数据集 | BM25 nDCG@10 | 重排序 nDCG@10 | 改进 |
|---|
| AguAna | 0.47 | 0.68 | 44% |
| Climate-FEVER | 0.19 | 0.33 | 80% |
| DBPedia | 0.32 | 0.45 | 40% |
| FEVER | 0.69 | 0.89 | 37% |
| FiQA-2018 | 0.25 | 0.45 | 76% |
| HotpotQA | 0.6 | 0.77 | 28% |
| Natural Questions | 0.33 | 0.62 | 90% |
| NFCorpus | 0.33 | 0.37 | 12% |
| Quora | 0.81 | 0.88 | 9% |
| SCIDOCS | 0.16 | 0.20 | 23% |
| Scifact | 0.69 | 0.77 | 12% |
| Touche-2020 | 0.35 | 0.36 | 4% |
| TREC-COVID | 0.69 | 0.86 | 25% |
| MS MARCO | 0.23 | 0.42 | 85% |
| CQADupstack (avg) | 0.33 | 0.41 | 27% |
使用 Elastic Rerank 模型对 BM25 检索的前 100 个文档进行 BEIR 重排序的每个数据集的 nDCG@10。
架构
正如我们之前讨论过的,语言模型的训练通常分多个步骤进行。第一阶段训练采用随机初始化的模型权重,并针对各种不同的无监督任务(例如掩码标记预测)进行训练。然后,在称为微调的过程中,针对进一步的下游任务(例如文本检索)训练这些预训练模型。大量经验证据表明,预训练过程会生成有用的特征,这些特征可以在称为迁移学习的过程中重新用于新任务。与单独训练下游任务相比,生成的模型显示出明显更好的性能和显著缩短的训练时间。这种技术是基于 Transformer 的 NLP 在 BERT 之后的许多成功的基础。
确切的预训练方法和模型架构也会影响下游任务的性能。对于我们的重排序模型,我们选择从 DeBERTa v3 检查点进行训练。这结合了预训练文献中的各种成功思想,并在微调时在各种 NLP 基准测试中提供了与模型大小相关的最先进性能。
简单总结一下这个模型:
- DeBERTa 引入了一种分离的位置和内容编码机制,使其能够学习内容的隐藏表示与序列中其他标记的位置之间更细致的关系。我们推测这对于重排序尤其重要,因为匹配查询和文档文本中的单词并比较它们的语义可能是关键因素。
- DeBERTa v3 采用了 ELECTRA 预训练目标,它以 GAN 风格尝试同时训练模型以提供有效的假标记并学习识别这些假标记。他们还提出了对该过程参数化的一项小改进。
如果您感兴趣,可以在这里找到详细信息。
对于第一个版本,我们训练了该模型系列的基本变体。它有 1.84 亿个参数,但由于其词汇量大约是 BERT 的 4 倍,因此主干只有 8600 万个参数,其中 9800 万个参数用于输入嵌入层。这意味着推理成本与 BERT base 相当。在我们的下一篇博客中,我们将探讨预算受限的重排序的最佳策略。无需赘述,我们计划通过蒸馏训练该模型的更小版本。
数据集和训练
每当您在模型上训练新任务时,总是存在忘记重要信息的风险。因此,我们训练 Elastic Reranker 的第一步是尽最大努力从 DeBERTa 中提取相关性判断。我们使用标准池化方法;特别是,我们添加了一个执行以下操作的头:
- 计算 A(D(L(h([CLS])))) ,其中 A 是 GeLU 激活, D 是 dropout 层, L 是线性层。在预训练中, [CLS] 标记表示 h([CLS]) 用于下一个句子分类任务。这与相关性评估非常吻合,因此将其用作头的输入是很自然的选择。
- 计算输出激活的加权平均值以对查询-文档对进行评分。
我们训练头部参数以收敛,冻结模型的其余部分,在我们完整训练数据的子集上。此步骤会更新头部以从预训练的 [CLS] 标记表示中读出它可以用于相关性判断的有用信息。执行这样的两步微调在 BEIR 上的最终 nDCG@10 中产生了大约 2% 的改进。
通常使用对比方法来训练排名任务。具体来说,将查询与一个相关(或正)文档和一个或多个不相关(或负)文档进行比较,并训练模型以选择相关文档。与其使用纯对比损失(例如最大化正文档的对数概率),不如使用强大的教师模型来提供文档相关性的真实评估。这种选择可以处理诸如负例错误标记之类的问题。与仅最大化相关文档的对数概率相比,它还为每个查询提供了更多信息。
为了训练我们的交叉编码器,我们使用教师提供一组分数,从中我们使用 softmax 函数计算每个查询的正负文档的参考概率分布,如下所示:
P(q, d) = \frac{e^{score(q,d)}}{\sum_{d' \in p \cup N} e^{score(q,d')}}
这里,q 是查询文本,p 是正文本,N 是负文本集,d∈p∪N,score 函数是交叉编码器的输出。
我们使用此参考分布最小化交叉编码器分数的交叉熵。我们还尝试了 Margin-MSE 损失,它在训练 ELSER 时效果很好,但发现交叉熵对于重排序任务更有效。
之所以采用整个公式,是因为将逐点排名解释为评估每个文档与查询相关的概率是很自然的。在这种情况下,最小化交叉熵相当于通过最大似然拟合概率模型,并赋予这种估计器良好的属性。与 Margin-MSE 相比,我们还认为我们获得了收益,因为交叉熵允许我们了解所有分数之间的关系,因为它可以通过精确匹配参考分布来最小化。这是相关的,因为正如我们下面讨论的,我们训练了多个负例。
对于教师,我们使用强大的双编码器模型和强大的交叉编码器模型的加权平均集成。我们发现双编码器对负例提供了更细致的评估,我们假设这是由于大批量训练导致每批对比数百万个不同文本。然而,交叉编码器在区分正负例方面做得更好。事实上,我们预计在这个领域会有进一步的改进。具体来说,对于模型选择,我们使用了一个小而有效的代理来执行不同的检索任务,我们计划探索是否在该任务上对我们的教师进行黑盒优化是有益的。
训练数据集和负采样对于模型质量至关重要。
我们的训练数据集包含开放问答数据集和具有自然对的数据集(例如文章标题和摘要)的混合。我们对这些应用了一些基本清理和模糊重复数据删除。我们还使用开源 LLM 生成了大约 18 万对具有不同相关度的合成查询和段落。我们使用了多阶段提示策略来确保该数据集涵盖不同的主题和各种查询类型,例如关键字搜索、精确短语匹配以及长短自然语言问题。总的来说,我们的训练数据集包含大约 300 万个查询。
人们普遍观察到,质量会随着重排序深度而下降。通常,难负挖掘使用检索结果的浅层采样:它会搜索每个查询的最难负例。文档多样性随着检索深度而增加,我们认为典型的难负挖掘因此没有为重排序器提供足够的多样性。特别是,训练必须证明查询和负文档之间关系的充分多样性。
仅仅增加整体查询和文档多样性并不能解决此缺陷;训练必须包括来自检索结果深尾的负面文档。出于这个原因,我们使用多种方法提取每个查询的前 128 个文档。然后,我们使用由其分数决定的概率分布从这个候选池中采样五个负例。对每个查询使用这么多负例并不典型;然而,我们发现增加采样的负例数量会显著提高最终质量。
为每个查询使用大型且多样化的负集的一个很好的副作用是它应该有助于模型校准。这是一个将模型分数映射到有意义的尺度的过程,例如相关性概率的估计。经过良好校准的分数可为下游处理或直接为用户提供有用信息。它们还有助于其他任务,例如选择截断结果的阈值。我们计划发布一些我们所做的研究校准策略的工作,以及它们如何有效地应用于不同检索和重排序模型的单独博客。
传统上,训练语言模型需要学习率调度才能获得最佳结果。这是一个根据训练进度更改梯度下降步长的乘数的过程。它带来了一些挑战:必须事先知道训练步骤的总数;它还引入了多个额外的超参数来调整。
最近的一些有趣工作表明,如果您采用新的权重更新方案(包括沿优化轨迹平均参数),则可以放弃学习率调度。我们采用了这种方案,使用 AdamW 作为基本优化器,并发现它产生了出色的结果并且易于调整。
总结
在这篇博客中,我们介绍了我们新的 Elastic Rerank 模型。它使用双编码器和交叉编码器模型的集合进行蒸馏,在精心准备的数据集上从 DeBERTa v3 基础模型进行微调。
我们展示了它提供了最先进的相关性重排序词汇检索结果。此外,它使用的参数比竞争模型少得多。在我们的下一篇博文中,我们将更详细地研究其行为,并重新审视我们在此处与之比较的其他高质量模型。因此,我们将提供一些关于模型和重排序深度选择的额外见解。
Elasticsearch 充满了新功能,可帮助您为您的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用版,或立即在您的本地机器上试用 Elastic。